

7 Doodles That Explain Machine Learning Better Than Your $3,000 Online Course

Why complicate something that can be drawn on a napkin?
I spent 15 years watching brilliant engineers completely fail to explain machine learning to executives, product managers, and even other developers.
The pattern was always the same:
Show intimidating math equations
Use unnecessarily complex jargon
Make everyone feel stupid
Wonder why no one approves their ML budget
After seeing this happen at three different tech giants, I started drawing these concepts on whiteboards with simple stick figures. The results were immediate: people finally understood what we'd been trying to explain for months.
So today, I'm sharing the 7 doodles that have helped thousands of people understand machine learning without the usual confusion, self-doubt, and expensive courses that leave you more confused than when you started.
All it takes is a pen and the ability to stop making things more complicated than they need to be.
1. ML Model = Chef's Recipe

Every ML model is just a recipe that transforms raw ingredients (data) into something useful.
The simplest explanation is:
Your data (x) is like raw ingredients (apples)
Your labels (y) are the instructions (recipe)
Your model is the chef who learns to transform inputs to outputs
The weights (θ) are the "secret sauce" the chef develops over time
Just like a chef adjusts their techniques over time to create better food, your model adjusts its weights to create better predictions.
The magic of ML isn't some mysterious black-box wizardry—it's just a function that learns how to transform inputs (apples) to outputs (pie) by learning from examples.
2. The Pain Theory of Loss Functions

When your model makes a mistake, it needs to feel pain to improve. That's what loss functions do.
The two most common loss functions can be understood through types of pain:
MAE (Mean Absolute Error):
Like death by 1,000 papercuts
Each error contributes equally to the pain
Linear penalty (consistent punishment regardless of size)
More robust to outliers (one huge error doesn't dominate)
MSE (Mean Squared Error):
Like one massive punch
Small errors get mercy, big errors get DESTROYED
Quadratic penalty (x²) that grows exponentially with size
Creates smoother gradients for training
The fundamental rule: Your outliers choose your loss function! If you have crazy outliers, they'll dominate your MSE calculations. If errors should all be treated equally, go with MAE.
3. How Models Learn: The Blindfolded Skier

Gradient descent—the most fundamental ML algorithm—is just a blindfolded skier hunting for the lowest point in a valley.
What's happening under the hood:
The skier can't see the entire mountain (your model doesn't know the perfect weights)
They can only feel which way is downhill from their current position (gradient)
They take steps in that direction (learning rate * gradient)
Sometimes they end up in a small valley instead of the deepest one (local minimum)
The equation step = -η∇L is just fancy math for "go downhill."
This is why setting your learning rate (η) is crucial:
Too small: your skier takes forever to reach the bottom
Too large: your skier flies off the mountain (training diverges)
And that "good enough" point where your boss stops complaining? That's your local minimum.
4. The Eternal Circle of ML Suffering

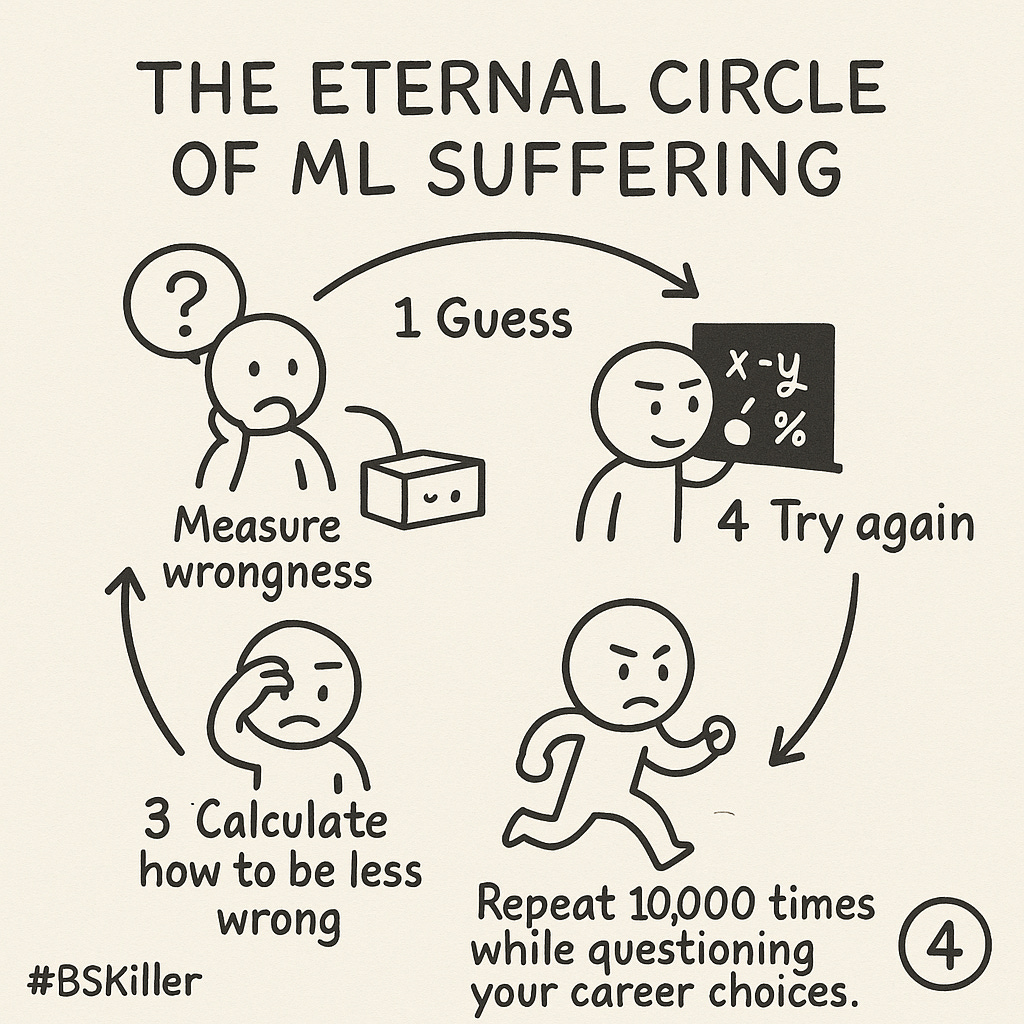
Every ML model goes through the same training loop thousands of times:
Guess (and probably be wrong)
Measure wrongness (feel shame)
Calculate how to be less wrong (backpropagate)
Try again (still wrong, but less!)
This cycle repeats for every batch of data, thousands of times, until your model is finally "good enough" (or you run out of compute budget).
What separates professionals from novices is understanding that this cycle never reaches perfection—it's about finding the point where your model's mistakes are acceptable for your use case.
5. The Goldilocks Principle of ML

Every ML model falls into one of three categories:
Underfit (Too Simple):
Like explaining rocket science with a crayon
High bias, misses important patterns
Will fail spectacularly on ALL data
Example: Using a linear model for complex nonlinear patterns
Just Right:
Captures meaningful signals without memorizing noise
Balances bias and variance
Will work most of the time (miracle!)
Example: Having just enough complexity to model the underlying pattern
Overfit (Too Complex):
Like a stalker who memorized your phone number but can't recognize you with sunglasses
Perfect on training data, useless in real life
High variance, crumbles on new data
Example: A model that learned that all cats in your training data had white paws, so it can't recognize cats with black paws
This is the machine learning equivalent of the timeless Goldilocks story—not too simple, not too complex, but just right.
6. The ML Chef's Golden Rule

Never taste-test with the dough you're still kneading.
This is the single most violated principle in machine learning. Your data must be split:
80% Training Data:
This is where you obsess, iterate, and mess up
Play with it, tune your model, do whatever you want
The kitchen where all the experimentation happens
20% Test Data:
FORBIDDEN KNOWLEDGE! Touch = instant failure
The ultimate truth of your model's performance
Like the final taste test of your recipe
Peeking at your test data during training is the cardinal sin of ML. It's like practicing for a test with the actual test questions—it leads to the illusion of performance without real generalization.
7. Model on a Diet: Regularization

Sometimes your model is trying TOO hard to fit the training data perfectly. Regularization puts it on a diet.
L2 Regularization (Ridge):
Every weight pays a tax (λw²)
Shrinks all weights to make the model smoother
Like attaching rubber bands to pull weights toward zero
Good for preventing high variance
L1 Regularization (Lasso):
Some weights get ELIMINATED (brutal but effective)
Drives some weights to exactly zero
Great for feature selection (identifying what actually matters)
Creates sparse models that use fewer features
Your model will desperately plead, "Please stop shrinking my parameters!" But regularization is tough love—it's making your model more robust for the real world.
Why These Simple Explanations Matter
The most dangerous thing in machine learning isn't what you don't know—it's thinking you understand something when you don't.
These doodles work because they:
Connect complex ideas to familiar concepts (chefs, skiing, Goldilocks)
Eliminate unnecessary jargon that gatekeeps knowledge
Create visual anchors that stick in your memory
Provide practical insights beyond the theory
After showing these doodles to hundreds of engineers, executives, and students, I've watched the same lightbulb moment happen over and over: "Wait, that's ALL machine learning is doing?"
Yes, that's it. Machine learning isn't magic—it's methodical. Once you understand these core concepts, everything else becomes clearer.
What's Next: Your ML Knowledge Journey
If these doodles helped you, I'm creating a full series breaking down more concepts:
Attention mechanisms and transformers
Convolutional neural networks
Reinforcement learning
Ethics and bias in ML
Which concept would you like me to doodle-explain next? Let me know in the comments.
And remember: if someone can't explain an ML concept with a simple drawing, they probably don't understand it well enough themselves.
Subscribe to BSKiller for weekly BS-free explanations of AI and ML concepts that actually make sense. No unnecessary complexity, no gatekeeping—just clear explanations that help you understand and implement the concepts that matter.